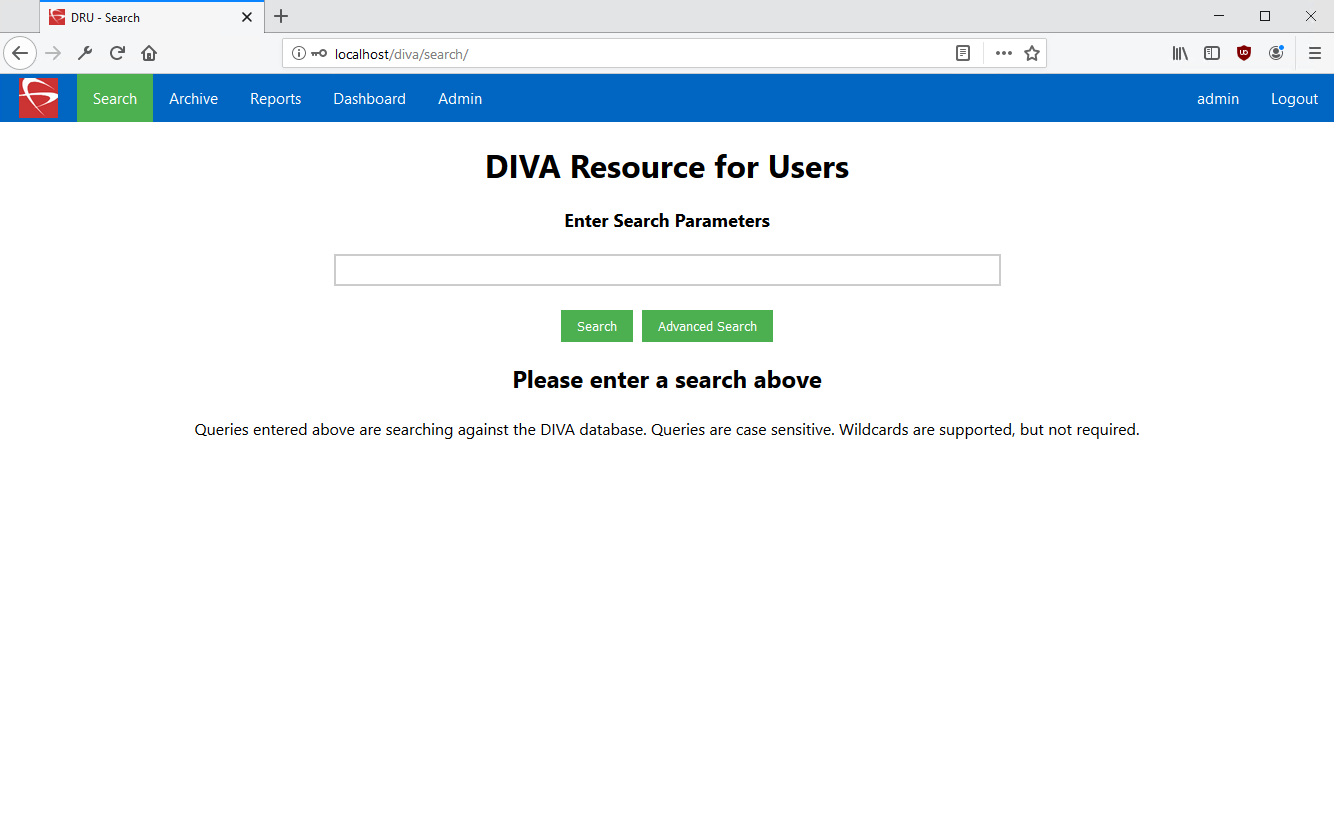
DRU (DIVA Resource for Users)
I have spent most of my professional career working on the technical side of media. During that time I have spent a lot of time working with asset management systems and helping to better integrate them into workflows. One of the systems found (previously) at several sites is Oracle’s DIVArchive, formerly by FrontPorch Digital.
DIVA at its core is a library of assets and their locations on managed disk and LTO tape. It can be used directly or in combination with other systems through the extensive API. DRU was designed to fill a specific gap I encountered, but it is flexible enough that I believe it can be helpful in many more ways.
The gap I encountered was the DIVA system had been in use for several years before the new user frontend was put into place. During the migration none of the historical data was imported into the new system meaning that the only source of data truth was a collection of spreadsheets. The data was being migrated, but it was a tedious process that required a system admin to export reports for time frames and send them to someone else who would clean up the data and import them it into the new system. DRU started as a simple way to self-serve the reports to free up time of the system administrators and then grew to facilitate several other functions.
In its current state DRU will run from any web browser and supports the following functionality:
- Search against the entire DIVA database
- Allow deep inspection of selected objects
- Restore objects to custom destinations
- Restrict functionality to definable users or AD groups
- Allow csv export of archive reports for user definable dates
DRU is available on Github. You can find the installation guide and complete documentation there.